Natural Language Processing(NLP)
-
목적: 단순히 하나의 개별 단어를 이해하는 것을 넘어, 해당 단어들의 문맥을 이해하려는 것.
-
e.g. 전체 문장 분류, 문장 내 단어 분류, 텍스트 컨텐츠 생성, 질의에 대한 정답 추출, 입력 텍스트로부터 새로운 문장 생성.
Pipeline
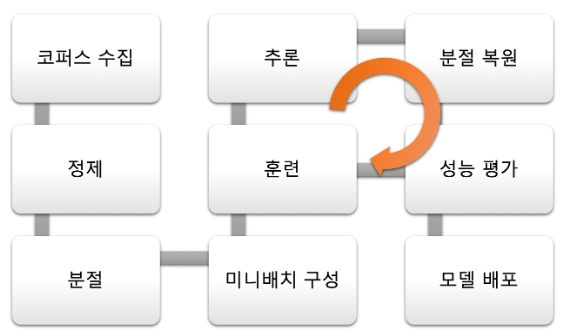
- 코퍼스 수집
- 뉴스 기사, 드라마/영화 자막, 위키피디아 등 다양한 소스에서 수집.
- 정제
- 문장 단위로 정렬, 특수 문자 등 노이즈 제거.
- 분절
- 각 언어별 형태소 분석기(POS tagger) 또는 분절기(Tokenizer, Segmenter) 사용하여 띄어쓰기 정제.
- 언어에 따라 Encoding 수행.
- 어휘 목록 구성.
- 미니배치 구성
- 미니배치 내의 문장의 길이가 최대한 같도록 통일.
- 실제 훈련 시에는 미니배치의 순서를 임의로 섞어서 훈련.
- 훈련
- 데이터 양과 크기에 따라 디바이스 선택(CPU/GPU 병렬 사용).
- 추론
- 풀고자하는 문제에 따라 여러 도메인에 대한 테스트셋 생성.
- 각 도메인의 모델 및 알고리즘 성능 평가.
- 분절 복원
- 실제 사용되는 문장의 형태로 변환.
- 성능 평가
- 기계번역용 정량 평가 방법: BLEU
- 정성 평가 수행.
- 모델 배포(서비스)
- API 호출 또는 사용자로부터의 입력.
- 추론을 위해 실제 모델에 훈련된 데이터셋과 동일한 형태로 분절.
- 추론: 수행 속도에 대한 최적화.
- 분절 복원.
- API 결과 반환 또는 사용자에게 결과 반환.
단어 표현
- 국소 표현(Local Representation) = 이산 표현(Discrete Representation)
- 해당 단어 그 자체만 보고 특정값을 맵핑하여 단어를 표현하는 방법.
- 분산 표현(Distributed Representation) \(\subset\) 연속 표현(Continuous Representaion)
- 표현하고자 하는 단어의 주변을 참고하여 단어를 표현하는 방법.
- 단어의 의미, 뉘앙스 표현 가능.
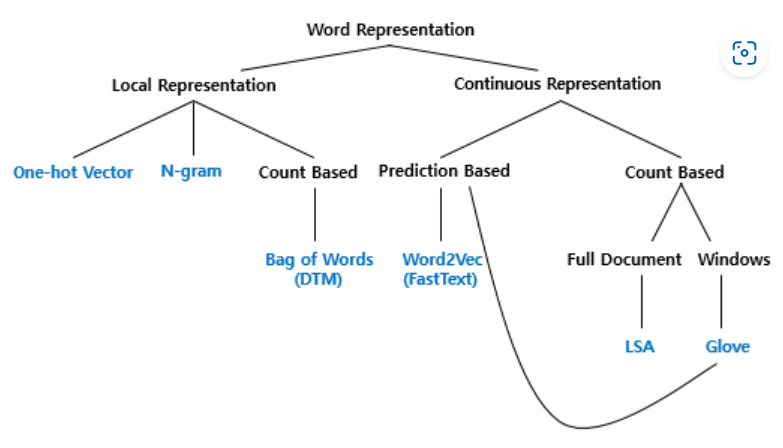
국소 표현(Local Representation)
Bag of Words
-
단어의 순서 고려 X, 단어들의 출현 빈도(frequency)에만 집중.
-
분류 문제나 여러 문서 간의 유사도를 구하는 문제에 사용.
Document-Term Matrix, DTM
-
서로 다른 문서들의 BoW들을 결합한 표현 방법.
-
한계
- 희소 표현으로 공간적 낭비와 계산 리소스 증가.
Term Frequency-Inverse Document Frequency, TF-IDF
-
DTM 내의 각 단어에 대한 중요도를 가중치로 주는 방법
-
문서의 유사도를 구하는 작업, 검색 시스템에서 검색 결과의 중요도를 정하는 작업, 문서 내에서 특정 단어의 중요도를 구하는 작업 등에 사용.
-
\(tf(d,t)\): 특정 문서 \(d\)에서의 특정 단어 \(t\)의 등장 횟수.
-
\(df(t)\): 특정 단어 \(t\)가 등장한 문서의 수.
\[idf(t) = log(\frac{n}{1+df(t)})\] \[TF-IDF = tf(d,t) \times idf(t)\] -
TF-IDF 값이 낮으면 모든 문서에 자주 등장하는 단어, 중요도 낮음.
-
TF-IDF 값이 높으면 특정 문서에만 자주 등장하는 단어, 중요도 높음.
벡터 유사도
- 코사인 유사도(Cosine similarity)
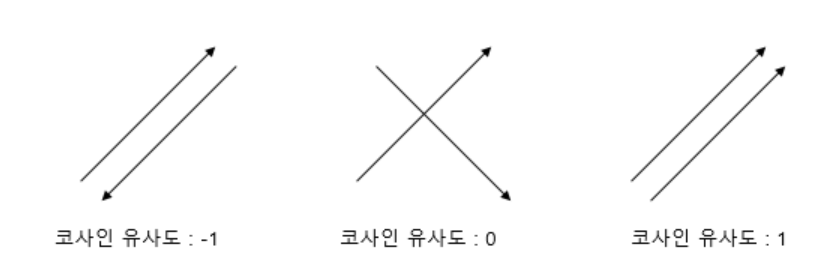
- -1 ~ 1 사이의 값을 가지며, 1에 가까울수록 유사도가 높음.
-
유클리드 거리(Euclidean distance)
\(\sqrt{(q_{1}-p_{1})^2+(q_{2}-p_{2})^2+\dots+(q_{n}-p_{n})^2} = \sqrt{\sum_{i=1}^n (q_{i}-p_{i})^2}\)
- 값이 작을수록 가깝다는 뜻이며, 유사도가 높음.
-
자카드 유사도(Jaccard similarity)
\(J(A,B) = \frac{\vert A \cap B \vert}{\vert A \cup B \vert} = \frac{\vert A \cap B \vert}{\vert A \vert + \vert B \vert - \vert A \cap B \vert}\)
- 0 ~ 1 사이의 값을 가지며, 두 집합이 동일하면 1, 공통 원소가 없다면 0.
분산 표현(Distributed Representation)
Word Embedding
- 단어를 벡터로 표현하는 방법.
-
단어를 밀집 표현으로 변환.
- 밀집 표현(Dense Representation)
- 희소 표현 벡터의 차원을 줄여 조밀하게 맞춤.
- 벡터의 모든 값이 실수 값으로 변환.
- 결과: 밀집 벡터(=임베딩 벡터).
Word2Vec (이후 포스팅 예정)
- Word Embedding 방법 중 하나.
- 단어의 의미를 수치화.
Reference
-
Natural Language Processing with PyTorch Gitbook: https://kh-kim.gitbook.io/natural-language-processing-with-pytorch/00-cover-13/01-pipeline
-
딥러닝을 이용한 자연어 처리 입문: https://wikidocs.net/31767
Contact: iyhs1858@gmail.com